Der starke Fokus auf Kosten/Nutzen erfordert eine genauere Planung zukünftiger und post mortem Analyse vergangener Projekte. Das Multiprojektmanagement hat die Aufgabe anstehende Projekte einer einheitlichen Bewertung zu unterziehen. Vor dem Hintergrund knapper Investitionsbudgets stellt sich vor dem Anfang der Projekte die Frage nach strategischer Relevanz und Wirtschaftlichkeit. Die Ertragsmessung von IT-Projekten gilt bis heute zu den größten Herausforderungen. Die Probleme der monetären Quantifizierung von IT-Systemen liegen vor allem in der Darstellung dieser Erträge in Nutzengrößen.[1] Eine weitere Herausforderung besteht darin die Aufwände für diese Projekte im Vorfeld genauer zu schätzen um zugeteilte Ressourcen optimiert auszulasten. Ein Schätzverfahren für Projekte im MPM muss somit den Anforderungen, Projekte im Vorfeld nach deren Kosten/Nutzen zu bewerten und dem Wunsch nach exakten Informationen, gerecht werden. Valide Schätzungen der zu erwarteten Entwicklungsaufwände sind für IT-Projekte der erste und wichtigste Erfolgsfaktor. Die Genehmigung des Projektes durch das MPM hängt grundlegend von der Wirtschaftlichkeit des geplanten Projektes ab. Der Nutzen muss höher sein als die Kosten, sonst gelangt das Projekt nicht über den Projektantrag hinaus. Die Dringlichkeit einer aufwändigen Schätzung für IT-Projekte wird von den meisten Unternehmen unterschätzt. Der qualitative und kommerzielle Projekterfolg hängt maßgeblich von einer genauen Schätzung ab, mit der Voraussetzung, dass das geplante Produkt möglichst ausführlich spezifiziert ist. Doch gerade in der agilen Entwicklung ist eine möglichst exakte Produktspezifikation, wie sie im Wasserfallmodell zu finden ist, nicht möglich. Statt zu Projektstart auf der Basis eines detaillierten Pflichtenheftes einen fixen Projektplan für die Projektlaufzeit zu erstellen, wird in einem agilen Vorgehen wie SCRUM[2] das Projekt im Release Plan nur grob in Sprints[3] gesplittet, in denen, vom Entwicklerteam, definierte Funktionsumfänge bereitgestellt werden.[4] Fehler in der Schätzung haben in der Regel weitreichende und fatale Auswirkungen auf die Durchführung eines Projektes. Großzügige Schätzungen oder hohe Unsicherheitsgrade die den Blick auf die wesentlichen Aufgaben und Risiken vermeiden, werden für Entwicklungsprojekte schon mit dem Start zu einer hohen Bürde. Das nächsten Abschnitte stellen die gängigsten Schätzmethoden vor.
Übersicht bekannter Schätzmethoden
Die vermeintliche Genauigkeit algorithmischer Verfahren wird hoch gepriesen. In der Projektpraxis vieler Unternehmen werden diese Verfahren aber kaum genutzt. Die nächste Abbildung gibt einen Überblick und eine grobe Klassifizierung der bekanntesten Schätzmethoden.
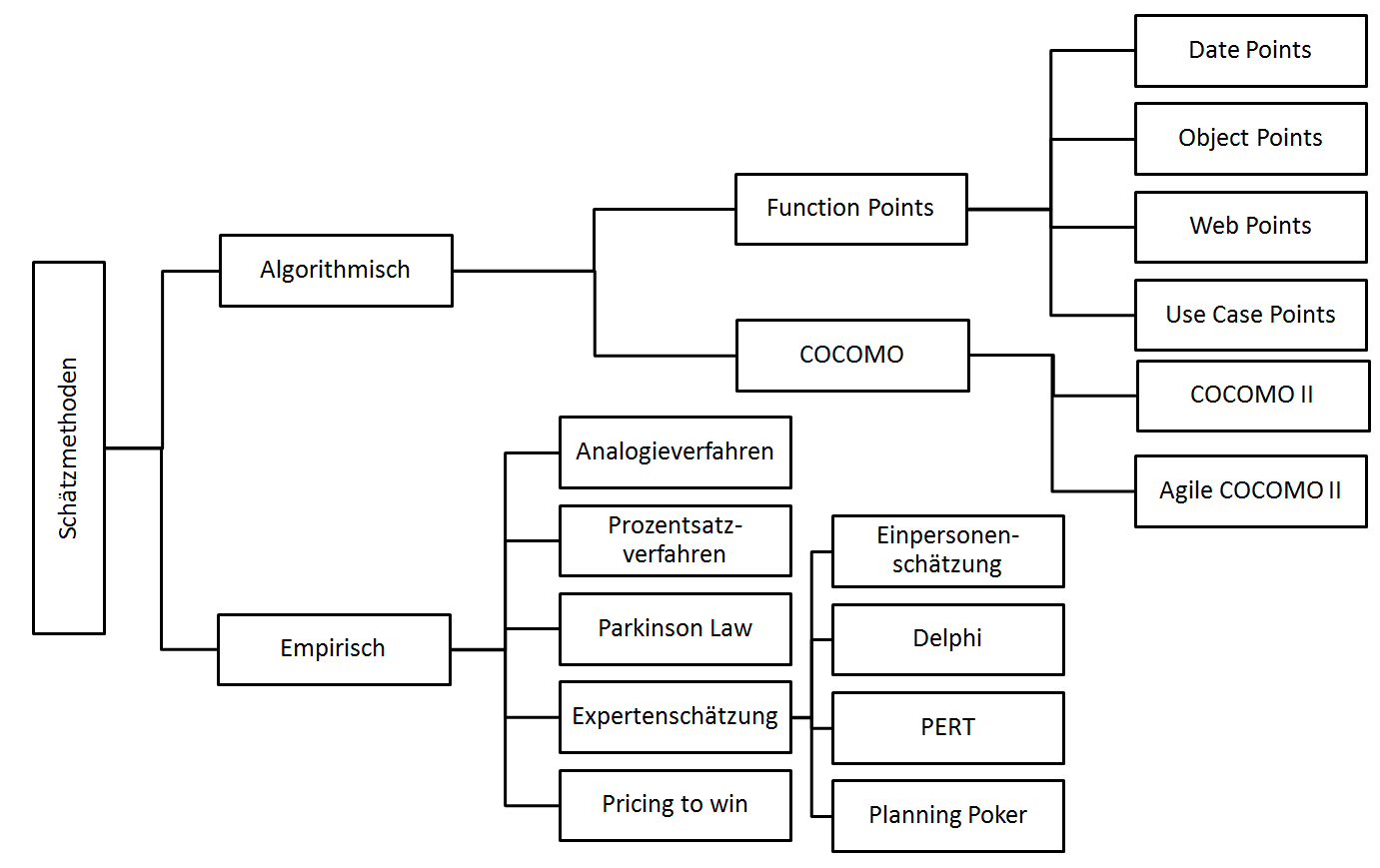
Klassifizierung der Schätzmethoden (in Anlehnung zu [5])
Empirische Schätzmethoden nutzen Erfahrungen und Referenzinformationen aus vergangenen Projekten deren Qualität stark von der Ähnlichkeit und Vergleichbarkeit abgeschlossener Projekte abhängt. Algorithmische Verfahren errechnen den Aufwand für ein Softwareprojekt mit Hilfe mathematischer Formeln und dem Durchlaufen einer Reihe von Schritten.
Analogiemethode
In der Analogiemethode werden Daten aus bereits abgeschlossenen Projekten als Grundlage für das zu schätzende Projekt herangezogen. Die vorherigen Projekte müssen vergleichbar mit dem geplanten Projekt sein. Der Aufwand der in der Vergangenheit angefallen ist, ist für Unterschiede in Aufgabenstellung und Realisierungsbedingungen entsprechend anzupassen. Das umzusetzende Projekt muss hohe Ähnlichkeiten zu bereits durchgeführten Entwicklungen aufweisen. Datenquellen können entweder eine eigene Erfahrungsdatenbank, empirische Untersuchungen oder Benchmarks sein. Die Verwendung der Analogiemethode wird mit einer Abfolge von 3 Schritten beschrieben.[6]
- Für das zu schätzende Projekt wird die aus der Aufgabenstellung, Umfang und Schwierigkeitsgrad ein Leistungsprofil erstellt.
- In zweiten Schritt werden die Unterschiede zwischen dem geplanten und dem abgeschlossenen Projekt ermittelt
- Im letzten Schritt wird das Delta zwischen abgeschlossenem und neuem Projekt bestimmt und bewertet.
Die Vorteile der Analogiemethodik sind die frühe Verfügbarkeit der Ergebnisse und der geringe Aufwand. Trotzdem lassen sich die Zahlen nicht optimal vergleichen weil eine hohe Voraussetzung bezüglich der Qualität der Daten besteht. Diese Methode ist somit für Prototypprojekte ungeeignet da vergleichbare Projekte meistens nicht vorhanden sind.[7]
Agile COCOMO II
Es gibt sehr viele Kostenschätzmodelle die auf Basis des COCOMO Modells entwickelt wurden. Agile COCOMO II ist eine solche Schätzmethode welches vom Center for Software Engineering der Univeristy of Southern California entwickelt wurde. Sie enthält das vollständig parametrische COCOMO Model und ist eine analogiebasierte Schätzung. Die webbasierte Anwendungen ist über die Seite der University of Southern California[8] zu erreichen. Noch gibt es zu dieser Methode zu wenige empirische Untersuchungen die einen Einsatz in der Praxis empfehlen.
Function Point Analyse (FPA)
Die Function Point Analyse (auch –Analyse oder –Methode) wurde in den 1970er und 1980er Jahren von Allan J. Albrecht für das Unternehmen IBM entwickelt. Die FPA misst die Größe einer Anwendung objektiv und unabhängig von technischen Randbedingungen.[9] Alan J. Albrecht hat die Problematik der Codemessung erkannt und führte das Function-Point-Maß ein, welches zur damaligen Funktionsmodellierung mit Funktionsbäumen (HIPO-Diagramm) passte. In einem weiteren Beitrag wurde die Zählmethode näher erläutert[10]. Ziel der FPA war die Eliminierung der Einflüsse, die sich aus der Verwendung unterschiedlicher Programmiersprachen ergeben und eine Schätzung zu einem früheren Zeitpunkt. Ausgangspunkt der Schätzungen sind Funktionen, die die Geschäftsvorfälle aus Sicht der Anwender abdecken sollen. Vorteile durch Function Points:
- Klar definierte Vorgehensweise
- Gute Vergleichsmöglichkeit
- Nicht Lines of Code sondern die Anforderungen stehen im Vordergrund
Nachteile:
- Anforderungen nicht immer einer Kategorie zuordenbar
- Großer Aufwand für große Projekte
- Kategorienaufgliederung veraltet und somit nach objektorientierten Kriterien nicht nachvollziehbar
- Baukastenprinzip vernachlässigt Abhängigkeiten und Synergien zwischen Programmteilen
Die FPA wurde noch einmal von Barry W. Boehm erweitert indem er den Fokus von der Umsetzungsdauer hin zur Komplexität eines Features verschoben hat. Warum trotzdem das Schätzen der Komplexität, wie man es aus dem Planning Poker in Scrum kennt, nicht weiter verfolgt werden sollte, wird im Blogbeitrag „Schätzmethoden in der Praxis“ unter „Warum Schätzen in abstrakten Maßen nicht ausreicht“ erläutert.
Bewertung der bekanntesten Schätzmethoden
Tendenziell gelten empirische Verfahren als weniger aufwändig, algorithmische Verfahren dafür als genauer und standardisierter. In der nächsten Tabelle werden die gängigen Bewertungen der wichtigsten Schätzverfahren aufgezeigt. [11]
| Methode | Komplexität | Vorteile | Nachteile |
| Function Points | eher hoch | Quasistandard, Transparenz | Datenbasis nötig, teilw. Subjektiv |
| COCOMO II | mittel bis hoch | gut für erste grobe Schätzung, Toolunterstützung | Größenbestimmung muss vorliegen |
| Expertenschätzung | gering bis mittel | schnell und flexibel | Subjektivität, Transparenz |
| Analogieverfahren | gering bis mittel | schnell für ähnliche Projekte | nicht anwendbar für neuartige Projekte, Datenbasis nötig |
| Prozentsatzmethode | gering | früh einsetzbar nach erster Phase | Datenbasis nötig, Varianz für neue Projekte |

